Machine Learning Insights
In this blog post, we show how machine learning can be used to attribute leads. Given information on a TV spot and the website traffic after the spot has aired, can we accurately identify the leads cause by TV?
At Adalyser, we are at the forefront of using machine learning (ML) to enable more targeted spending. The first question when faced with such a task is what method to use.
A gentle introduction to machine learning
Machine learning offers a variety of approaches that let computers “learn” based on data rather than explicitly being instructed how to do something. For this to work, we need some examples, such as a spots impact, and the thing we would like to predict, e.g. the number of leads that will result.
At first, we need to train our model. Initially, we guess the parameters of the model and try to predict the “label”. Then we change the parameters a little bit in order to improve our prediction. This process is repeated until our predictions stop getting better.
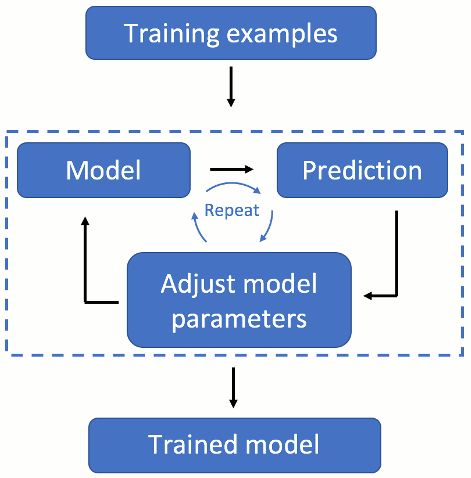
Once we have trained our model, we use it to predict the label on data for which we do not know the correct answer.
Let us try to predict the number of leads generated by a TV spot using the impact of the spot as our measurement. The simplest model is fitting a straight line between those two variables, let's call them the impact i and number of leads l. This is shown in the animation, where we add more and more training examples and update our model accordingly.
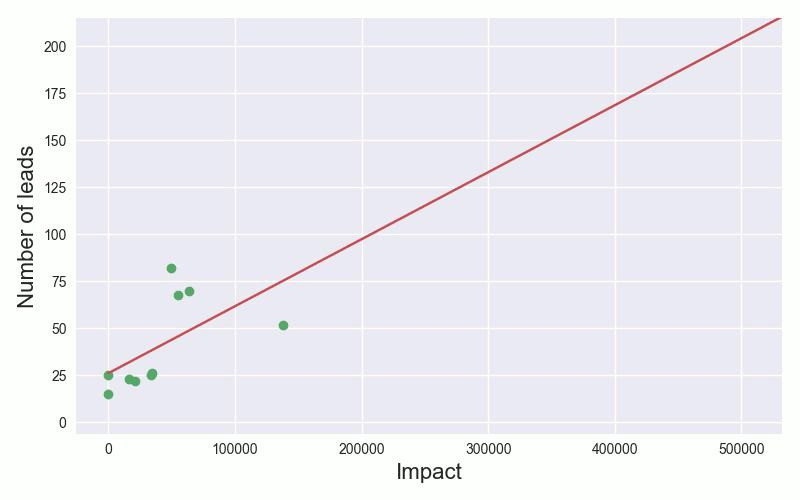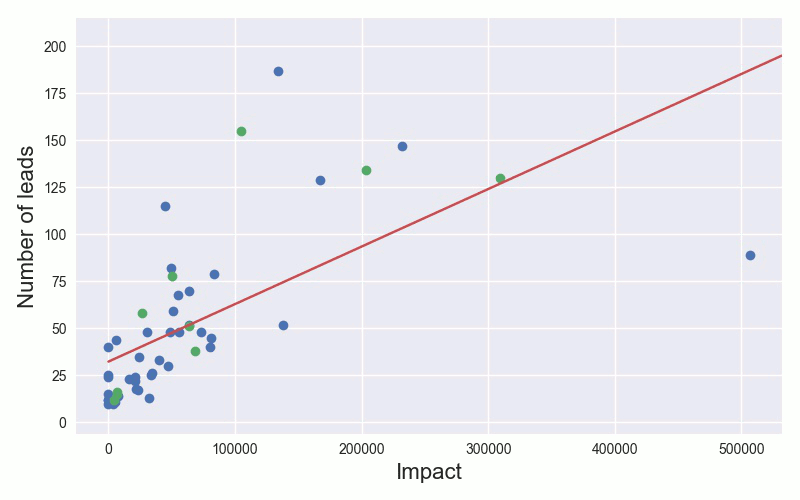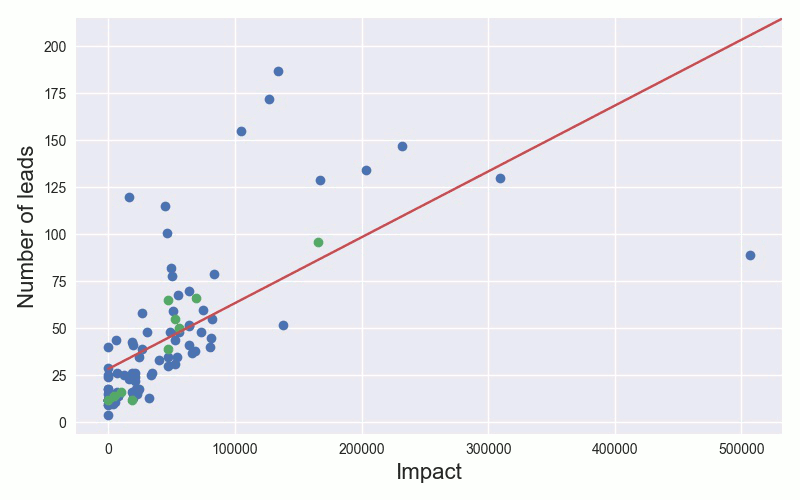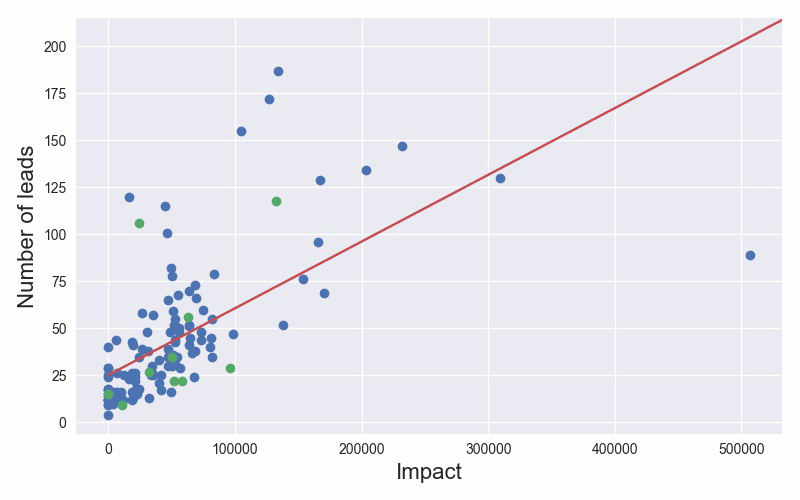
Once we have trained our model, we can use it to predict the number of leads we expect, given a spots impact. This is of course a simplistic example. In practice, we would consider many more variables, such as the type of product being sold, TV channel, time of day and use a more complex model than a straight line. This is what we do in the next section.
Applying machine learning
When choosing a model, there is an inherent trade-off between simplicity and predictive ability. Simple models are not able to represent all real world effects but are robust to the effects of noise, random variations in the data. This means that such models are likely to be as good at predicting the outcome of new data as they are on the training data. More advanced models can represent more complex relationships. However, such more flexible methods may just learn to approximate the data used for training and be bad at predicting other data. This is called overfitting.
Naive Bayes is a simple classifier that is nonetheless competitive at some tasks, such as text classification (e.g. spam filters). It is also often used as a baseline to compare other machine learning techniques against. For this reason, we will apply this to our data first, even if it is unreasonable to expect good results. After training, the Naive Bayes classifiers has an overall accuracy of 73%. While 90% of the leads not from TV were classified correctly, only 43% of leads from TV were correctly identified. This isn’t very useful yet, so we need to move to a more sophisticated machine learning technique.
Decision trees are a general method of predicting a value and data mining. They are robust to including variables that are irrelevant and trees naturally can deal with both numerical and categorical variables. However, they are prone to over-fit. There are several methods that combat this by building several trees and averaging them in some way. One such method is called a random forest (pun intended).
How accurately can we predict whether a lead was caused by television with a random forest? Using tracking and spot data, 88% of leads in our test data are labelled correctly. As with the Naive Bayes classifier, 91% of leads not from TV are classified correctly. However, in contrast to the Naive Bayes, 81% of leads from TV are also classified correctly. As we only use spot and lead information, this can be used to identify visitors to a website in real time.
Can we do better than that? The most versatile machine learning technique is training neural networks. These have been shown to beat humans in complex tasks such as categorizing images or recognizing handwritten digits. However, for the case of a single lead and spot, this yields the same accuracy of 88%. This suggests that there is insufficient information in the tracking data to achieve a greater accuracy: some leads that look identical are from different sources and more information is needed to distinguish them. We will look at such approaches in future blog posts.